Learning Databases internals
In this blog post, I will share my journey of learning about database, their internals, and how they work. This is a topic that has always fascinated me and felt a bit like magic how Postgres or SQLite could become so useful and be the core layer of so many applications.
Where to start?
I started by doing the great Databases Systems: Fall 2024 course by CMU hosted by Andy Pavlo. The course is fully available online (with lectures in Youtube) and is such a great resource to learn about databases. The course covers a wide range of topics, including:
- Relational model and SQL: intro to the relational model and how SQL is used to access it.
- Database storage: how data is stored in disk, what disk pages look like and the difference between tuple oriented storage and log structured storage (think PostgreSQL vs RocksDB).
- Memory management: this section goes into how do we move data from disk into memory and back to disk in an efficient way.
- Indexing: goes into the details of how indexes are implemented, the most widely used index data structure is the B+ tree.
- Query execution & optimization: explains how queries are executed, planned and optimized to run as fast as possible.
- Concurrency control: introduces the ACID correctness criteria into how multiple database transactions can coexist with each other withot causing inconsistent results.
While the lectures and materials of this course are great, my favorite part of the course is their main project which consists of building some of the internal of a Disk-oriented Database System (DBMS).
Bustub: CMU learning DBMS – Project work
The great folks at CMU have developed Bustub as a learning DBMS where students can build different components of it for their own learning. This helps connect the theory with the practical aspects of it. Another nice thing of the project is that the course has some tests accessible online in Gradescope where you can submit your code to verify it works as expected.
In the version of the course I took (Fall 2024) there were a few projects to tackle, I’ll go into detail into what each of them ask without giving any solutions as that is where the fun of the course is.
Project 1: Buffer pool manager
In this first task we had to implement a buffer pool manager, which is a data structure in charge of loading/unloading database pages from and to disk. It is a very elegant design since you basically initialize it with a specific maximum number of pages it can keep in memory and it provides the following high level API:
ReadPageGuard ReadPage(int page_id): it reads a page from disk (or re-uses its cached version) and returns a read-only pointer to the page contents. Note that it keeps a read lock on the page to make sure that this page can be read by multiple threads at the same time and that it does not get evicted accidentally.WritePageGuard WritePage(int page_id): aquires an exclusive latch (aka lock) on the given page and allow us to change the contents of the page. Once theWritePageGuardobject gets destroyed it is the job of the buffer pool to make sure it gets written to disk.
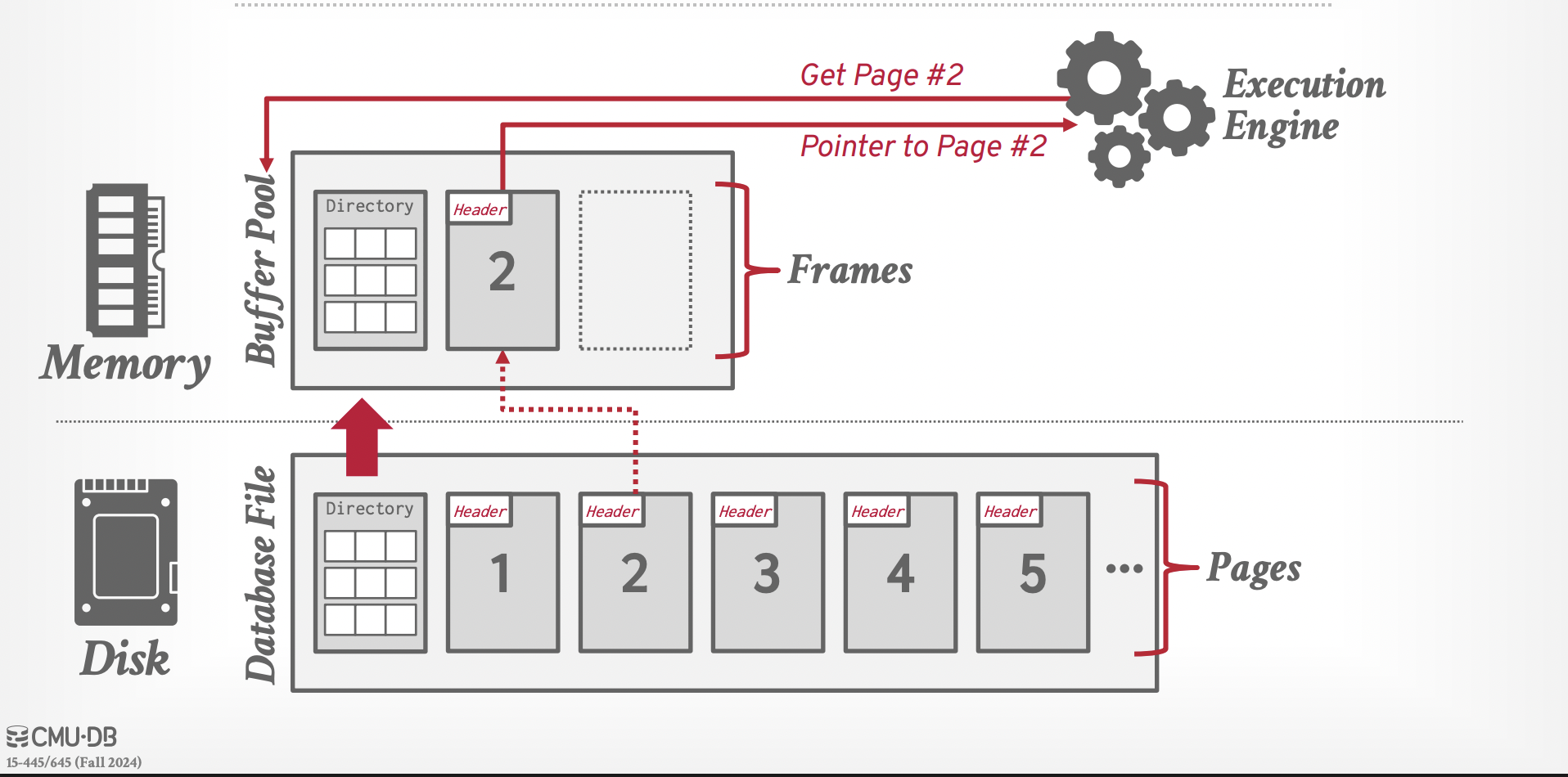
Note that a very important part of the buffer pool is to decide how to evict pages from memory once we don’t have any more memory available to us.
Project 2: B+ tree index
The second project was to implement a B+ tree index on the database so that we can do fast lookups or range scans on a given table column. A B+ tree is a tree data structure optimized for fast search and insertions but unlike Binary Search Trees it is meant to work well with its contents being stored in disk. To do this it optimizes for large sequential scans over many random disk accesses (which tend to be slow).
The core idea of a B+ tree is to generalize a binary search tree by having a single node holding many keys and values rather than only two, this makes it so that nodes tend to be much larger and can fill up entire disk pages, which in turn means a shallower tree with less jumps across nodes. The image below shows at a high level the picture of the tree.
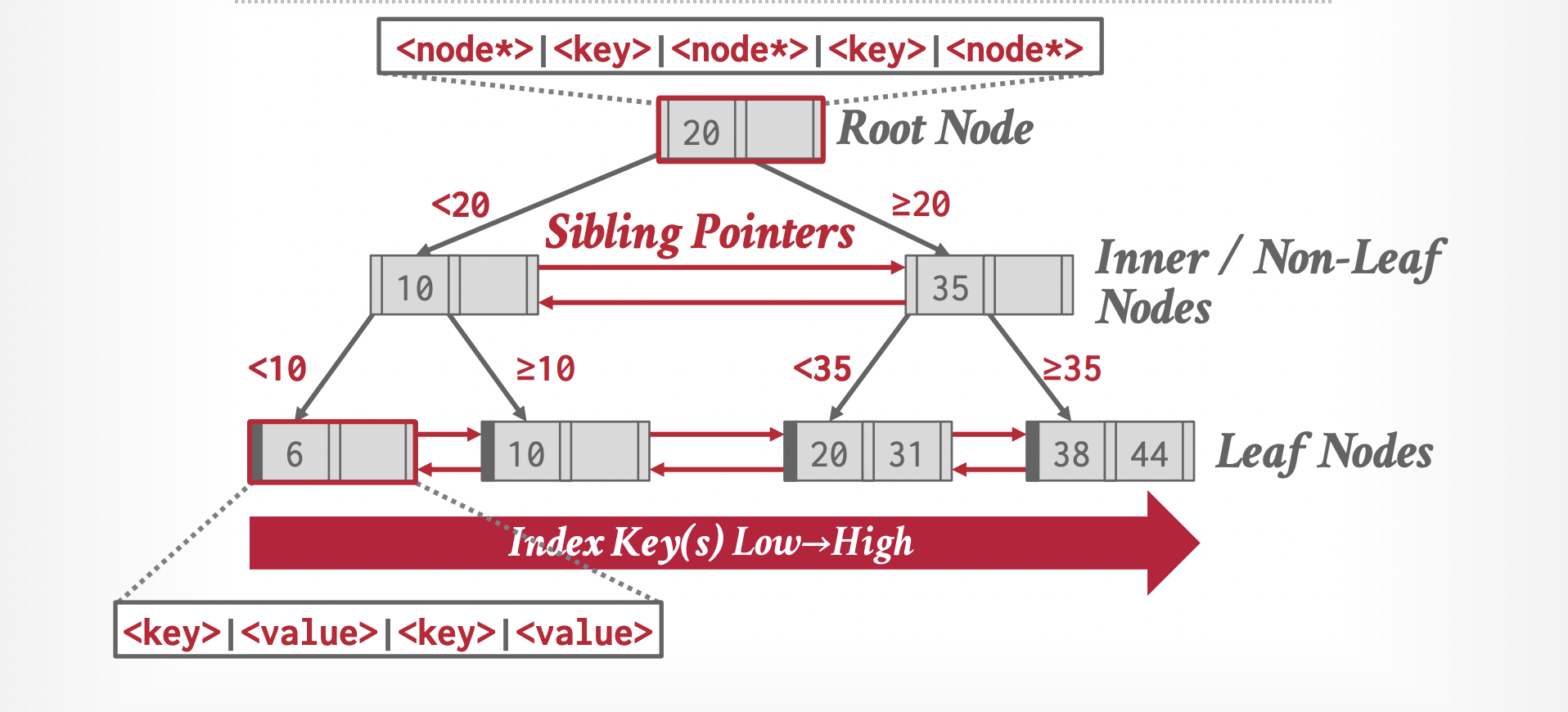
For this project we had to implement search, insertion and deletion as well as concurrency control for the tree. This was a challenging project since it gets tricky in how to merge nodes during deletion or how to split them during insertion.
Also the concurrency control part is extremely interesting since we want to optimize the B+ tree for many concurrent threads reading and writing without blocking the whole tree (specially the root since all access goes through the root of the tree).
Parting thoughts
I’m still going through the course, but so far the lessons learned have been really amazing and I can recommend to anyone using Databases to take a deep look at this to learn how they work to appreciate all the amazing engineering work put on it.